Week 8 - Database Design
This week we'll talk about general principles for designing a database. We'll look at constraints, indexes, and how normalization works up to the 3rd normal form.
"Normalizing" data means, roughly, cleaning and organizing data in a way that will make it as useful and easy to work with as possible inside of a relational database.

General Principles of Database Design
Today's lesson will get pretty abstract, so strap in!
Even if you don't walk away having committed to memory the details of, say, the Boyce-Codd normal form, here's what I want you to take away:
Some things to remember
- Data should be duplicated as little as possible.
- One-to-one relationships mean we have one too many tables.
- Many-to-many relationships mean we need a bridging table.
- One table for each type of entity (person, place, thing, event).
- One cell for 1 datum (piece of data).
- We maintain referential integrity with keys.
- We maintain data integrity with constraints.
- We maintain semantics with data types.
Come back to this at the end of the lesson and see if it all makes sense!

Relationship types
There are 3 types of relationships between tables, but only one of them is ideal!
One-to-one
A one-to-one relationship means that any row in your table is only referenced once by the other table. If that's the case, it's more efficient to store all the data in a single table.
Let's look at an example where students are always seated in the same desks:
This information can be more efficiently stored in a single table:
| Seating Table | |||
| StudentID | Student | Row | Column |
| 123456 | Birinder | 5 | 7 |
| 123457 | Amandeep | 6 | 5 |
| 123458 | Ryan | 6 | 7 |
Merging our one-to-one relationship into a single table eliminates the need for JOINs, and key columns required to make those joins happen.
When one-to-one relationships are ok
There's a few circumstances where one-to-one relationships are totally ok!
- If you anticipate a one-to-many relationship. Will the school start having night classes someday? Then it's ok to keep the desks table separate to accommodate multiple students.
- If you want to maintain semantic distinctions between entities. Do you need to record information about desks that aren't relevant to the students? Do you need to record information about the students that isn't relevant to their seating? You might want to keep the tables separate!
- The number of columns will be very large. If you're recording a lot of different types of information about individual entities, you might want to split your table for the sake of efficiency, particularly if some columns are usually left null.
Many-to-many
Trying to represent a many-to-many relationship without a bridging table (also known as a 'junction table', also known by many other names Opens in a new window) is a really bad idea.
Think of students and classes. Students have many classes and classes have many students. There are two reasons this is messy: 1) because we only want one piece of information per cell in our table, and 2) because only want one column per category of data. We can solve this by creating a 'joining table' that sits between them - a table that creates a one-to-many relationship with both tables.
In the students table below, we store the students' classes in an array, which violates our principle of "one cell for 1 datum".
In the classes table below, we try to add a column for each student - but different classes have different numbers of students, so how many columns do we need? In first-year university, I was in classes with hundreds upon hundreds of students!
Neither approach is a good way to represent a many-to-many relationship.
| Student Table | ||
| StudentID | Name | Classes |
| 123456 | Birinder | 1,4,5 |
| 123457 | Amandeep | 1,2,4 |
| 123458 | Ryan | 3,4,5 |
| Class Table | ||||||
| ClassId | Name | Student1 | Student2 | Student3 | Student4 | ... |
| 1 | Physics | 123464 | 123465 | 123466 | 123467 | ... |
| 2 | Chemistry | 123461 | 123462 | 123463 | 123464 | ... |
| 3 | Art | 123471 | 123472 | 123473 | 123474 | ... |
| 4 | Music | 123464 | 123465 | 123466 | 123467 | ... |
| 5 | Geography | 123466 | 123469 | 123470 | 123471 | ... |
If we instead create a "bridging" table, representing the relationships between the two entities (i.e. which student has which class), we can represent this "many-to-many" relationship in a sensible, efficient, and maintainable way.
One-to-many
Our solution above to the "many-to-many" relationship problem is to create an intermediary table that has a "one-to-many" relationship to both of the initial tables.
A one-to-many relationship means that the primary key of one table is referenced multiple times in another table. That's good! It's basically the purpose of a relational database - reducing repetition by referencing single instances of data.

Constraints
Constraints are rules about what data is allowed in our tables & columns.
You're already familiar with most constraints! We talked about them last time when we created definitions for columns, like NOT NULL, DEFAULT, etc.
Go back to those notes if you don't recall how we use the following:
- PRIMARY KEY
- NOT NULL
- UNIQUE
- DEFAULT
There's one other type of constraint that we have mentioned in the past, which we'll now look at in detail: the foreign key constraint.
Foreign Keys
A foreign key is simply a column in one table that references the primary key (or another UNIQUE column) of another table.
You're already familiar with this relationship - 9 times out of ten, these are the columns that we use to create our JOINs.
Since it plays such an important role in representing the relationships between tables, we can set up a number of rules (a constraint) to make sure our data keeps making sense (a.k.a. data integrity).
The syntax for creating a foreign key constraint is simple:
CREATE TABLE tableName (
id INT PRIMARY KEY,
otherTableId INT
REFERENCES {otherTableName}({otherTablePrimaryKeyCol})
);To create a foreign key constraint when creating a table, use the keyword REFERENCES, followed by the name of the other table, with the name of the referenced (primary key) column in parentheses.
The foreign key must have the same data type as the primary key it references.
Let's say you wanted to create a table for students, and a table for work placements, in a situation where each work placement would be assigned one student:
CREATE TABLE IF NOT EXISTS new_students (
student_id INT PRIMARY KEY,
name VARCHAR(255)
);
CREATE TABLE IF NOT EXISTS work_placements (
placement_id INT PRIMARY KEY,
student INT REFERENCES new_students(student_id),
country VARCHAR(60) DEFAULT 'Canada',
description VARCHAR(255)
);Foreign key constraint referential actions
By default, you cannot delete a row (or drop a table containing a row) that has another table referencing it via a foreign key.
If there is a foreign key value in one table that points to a primary key value in another table, the row with that primary key value is "protected".
This makes a lot of sense - if you set a foreign key, you're saying "I need to be able to get that data so this data makes sense". If you were to delete the data the foreign key refers to, you'd "orphan" that row.
Sometimes, however, you want to be able to delete or update rows without throwing an error (or having to manually delete the corresponding row first).
In order to set some custom process rules (known as 'referential actions') for our foreign key, we'll use a slightly different syntax. Instead of declaring the reference while defining the column, we'll define it after our columns are declared.
CREATE TABLE IF NOT EXISTS work_placements (
placement_id INT PRIMARY KEY,
student INT,
country VARCHAR(20) DEFAULT 'Canada',
description VARCHAR(255),
FOREIGN KEY (student)
REFERENCES new_students(student_id)
);Delete the foreign key row automatically
Let's say you want to delete a row, and all references to it. We'll use the referential action ON DELETE CASCADE
CREATE TABLE IF NOT EXISTS work_placements (
placement_id INT PRIMARY KEY,
student INT,
country VARCHAR(20) DEFAULT 'Canada',
description VARCHAR(255),
FOREIGN KEY (student)
REFERENCES new_students(student_id)
ON DELETE CASCADE
);Update the foreign key row automatically
Let's say you want to update the primary key value of a row, but maintain existing references to it. We'll use the referential action ON UPDATE CASCADE
CREATE TABLE IF NOT EXISTS work_placements (
placement_id INT PRIMARY KEY,
student INT,
country VARCHAR(20) DEFAULT 'Canada',
description VARCHAR(255),
FOREIGN KEY (student)
REFERENCES new_students(student_id)
ON UPDATE CASCADE
);Oh yah, you can set both these rules if you want:
CREATE TABLE IF NOT EXISTS work_placements (
placement_id INT PRIMARY KEY,
student INT,
country VARCHAR(20) DEFAULT 'Canada',
description VARCHAR(255),
FOREIGN KEY (student)
REFERENCES new_students(student_id)
ON DELETE CASCADE
ON UPDATE CASCADE
);Set the foreign key value to NULL automatically
Okay, let's say you've decided you're fine with orphaned data for whatever reason. Besides CASCADE, you can also define your referential action as SET NULL
CREATE TABLE IF NOT EXISTS work_placements (
placement_id INT PRIMARY KEY,
student INT,
country VARCHAR(20) DEFAULT 'Canada',
description VARCHAR(255),
FOREIGN KEY (student)
REFERENCES new_students(student_id)
ON DELETE SET NULL
);Altering foreign key constraints
Just like most aspects of our tables, we can ADD, or DROP foreign keys. There isn't an easy way to modify them, however - you're going to have to drop your foreign key and create a new one if you want to make changes.
Adding a foreign key to an existing table
Adding a foreign key to an existing table is pretty straightforward, if you remember our ALTER TABLE syntax:
ALTER TABLE work_placements
ADD FOREIGN KEY (student)
REFERENCES new_students(student_id)
ON DELETE SET NULL;Dropping a foreign key
Dropping a foreign key is harder, because you are not dropping the column, you are just dropping the constraint. How do we differentiate between the column and the constraint?
Well, it turns out that when we added the constraint, the database gave the constraint a name!
You can poke around in dBeaver to find out the name that was automatically given to your constraint.
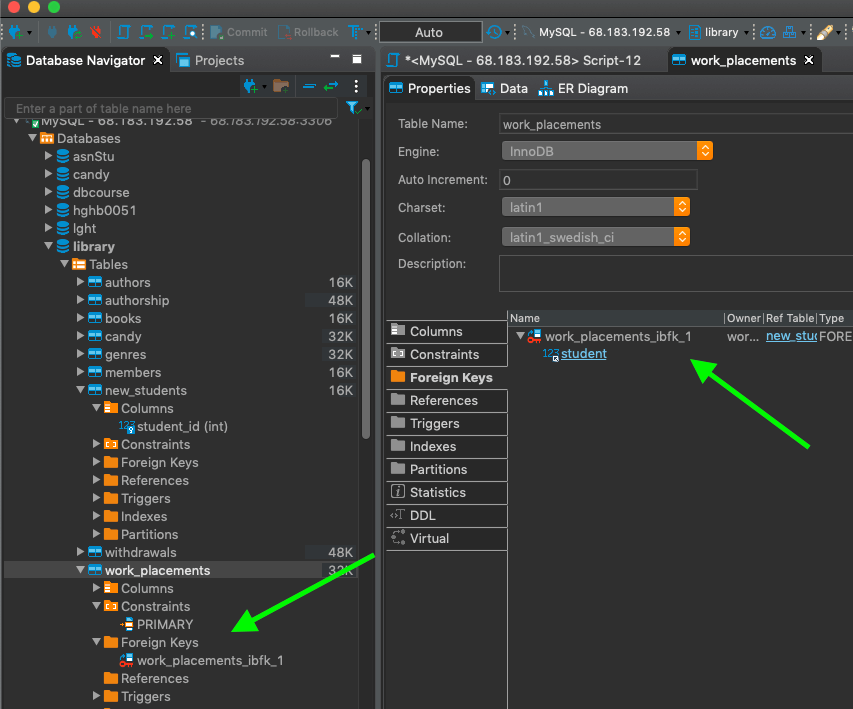
Rather than having our constraints automatically named, however, we can define a name for them. This makes them much easier to recognize and remember!
Here's the syntax for adding a named foreign key constraint:
CONSTRAINT {name} FOREIGN KEY ({column})
REFERENCES {otherTable}({otherTablePrimaryKeyColumn})So, if we create our table like this:
CREATE TABLE IF NOT EXISTS work_placements (
placement_id INT PRIMARY KEY,
student INT,
country VARCHAR(20) DEFAULT 'Canada',
description VARCHAR(255),
CONSTRAINT student_id_fk FOREIGN KEY (student)
REFERENCES new_students(student_id)
ON DELETE SET NULL
);...we'll have a custom, readable name for our foreign key.
Once you've named your foreign key, you can use that name (rather than the auto-generated name) to drop your foreign key, using the following syntax:
ALTER TABLE work_placements
DROP FOREIGN KEY student_id_fk;Naming your foreign keys is a good habit! I suggest you use this syntax when creating your tables.

Optimizing with indices
In MySQL (and most other RDBMSs), the database can create "indexes", much like the index in the back of a book - a way to look things up that is quicker than scanning the whole book (or table, as the case may be).
In fact, your database has already been doing this for you - when you declare a primary key, it's automatically indexed! This means that looking things up based on the primary key is much faster than looking things up based on other, non-indexed columns.
If indexing is so fast, why isn't everything indexed? Well, because indexes add to the complexity of your database structure. If you add a lot of indexes to speed up your read times, you could be doing it at the cost of slower write times.
A good rule of thumb is, aside from the primary key, you should only be explicitly declaring indexes on columns (or combinations of columns) that will be used a lot in your WHERE clauses.
Also, as with a lot of things to do with database optimization, you're also only going to see real, significant performance results if your database is really, really big.
All that being said, indexes are pretty easy to create and manage!
You'll usually want to create indexes when you're creating your tables.
Let's say, for the sake of argument, we know we're going to be running queries based on the student and country columns a lot:
SELECT * FROM work_placements
WHERE description = 'onsite'
AND country = 'Canada';We'd probably want to create an index when we make our table:
CREATE TABLE IF NOT EXISTS work_placements (
placement_id INT PRIMARY KEY,
student INT REFERENCES new_students(student_id),
country VARCHAR(60) DEFAULT 'Canada',
description VARCHAR(255),
INDEX (description, country)
);Indices & Uniqueness
Since it's entirely possible for a work placement to have the same description & country, we don't specify that the INDEX is unique. If we wanted to enforce uniqueness (making our indexing faster), we could write it as UNIQUE INDEX (description, country). This creates a kind of constraint - the database will reject insertions of duplicate values into unique indexes.
Now say you wanted to add an index to an existing table. Couldn't be easier:
CREATE INDEX {indexName}
ON {tableName}({columnName(s)});
Normalization
Normalization is a fancy way of talking about best practices for organizing data in a relational database. Let me be clear: you already have a practical understanding of most of this stuff already.
The reasons for learning about normalization are two-fold:
- They are good, abstract principles that can guide you if you're in an uncertain situation.
- They will make you sound fancy and academic, if you're into that.
Each level of normalization, or "normal form", is a prerequisite of the subsequent forms. You can't achieve the third normal form if you haven't already achieved the second normal form; you can't achieve the second normal form if you haven't achieved the first normal form.
There are various definitions of what constitutes the different forms - I'm gonna do my best to give you the simplest explanations that I can without going down a rabbit hole, or turning this into a CompSci class.
For those of you with a Computer Science degree - if you have a simpler way of explaining any of these, please let us know!
And if you hear me say something that isn't quite true (because the truth is it's much more complex)... feel free to clarify this for us in a quiet moment.
First Normal Form (1NF)
Here's the criteria for table data complying with the first normal form:
- Each row is uniquely identifiable (no duplicate rows).
- No cell contains more than one piece of data (i.e. no lists or arrays).
- There are no columns for identical data (i.e. student1, student2, student3, et al. in the class table).
Second Normal Form (2NF)
Second Normal Form criteria:
- Meets the 1NF criteria.
- Each row, outside of the key, is uniquely identifiable based on the entire primary key.
Now I know what you're thinking - you made a primary key column, and of course you auto-incremented it, so naturally every row is uniquely identifiable. But "primary key" in the context of normalization has a different definition.
We've been learning, up to this point, that each row should be assigned a value that is unique. Once we start to talk abstractly about database principles, we start using the term "primary key" to refer to the entity itself, as defined by the data we're storing about it (told you this would get overly think-y).
It might be helpful to think of the primary key in this context as "the entity the table is based on".
|-----Primary Key----| uh oh |
V
CourseID| Semester | #Places | Course Name |
-------------------------------------------------|
IT101 | 2009-1 | 100 | Programming |
IT101 | 2009-2 | 100 | Programming |
IT102 | 2009-1 | 200 | Databases |
IT102 | 2010-1 | 150 | Databases |
IT103 | 2009-2 | 120 | Web Design |In this example, what identifies the actual course entity is the Course ID, plus the semester. Makes sense, right? If you were to take one course in two different semesters, you're paying tuition twice, because that's two courses.
The course name only depends on part of the primary key. It can be moved into a separate table that maps Course IDs to Course Names, and that would reduce repetition.
Third Normal Form (3NF)
The 3rd normal form requires that no column data depends on another column that is not the primary key.
Say you've got a column for school courses that has columns for the course id (the primary key), the teacher's id, and the teacher's name. This is not 3NF, because the teacher's id and the teacher's name are dependant on one another.
To make this database 3NF, you'd move the teacher's name into a different table (referenced by the teacher id). This way if you change which teacher is assigned to the class, you're only updating one column in the class table.
Boyce-Codd Normal Form (BCNF, a.k.a. 3.5NF)
The first three normal forms were defined by a fella named Edgar F. Codd Opens in a new window in 1970. He and Raymond Boyce Opens in a new window, in 1974, felt that an extra step could be taken to normalize data, covering edge cases where a table that meets 3NF has multiple overlapping "candidate keys" (combinations of two or more columns that form unique identifiers where there are no other unique identifiers comprised of less columns).
For the life of me, I couldn't find a way to illustrate or explain this without taking up more of your time than I could justify. The wikipedia article is the most concise explanation I could find, so if you're interested, go nuts Opens in a new window. I promise BCNF won't show up on your quizzes or whatever.
Fourth Normal Form (4NF)
4NF, by contrast, is delightfully simple. If there are two columns that are related to the primary key independent of one another, then they can be separated out into different tables.
| Restaurant | Pizza Variety | Delivery Area |
|---|---|---|
| A1 Pizza | Thick Crust | Springfield |
| A1 Pizza | Thick Crust | Shelbyville |
| A1 Pizza | Thick Crust | Capital City |
| A1 Pizza | Stuffed Crust | Springfield |
| A1 Pizza | Stuffed Crust | Shelbyville |
| A1 Pizza | Stuffed Crust | Capital City |
| Elite Pizza | Thin Crust | Capital City |
| Elite Pizza | Stuffed Crust | Capital City |
| Vincenzo's Pizza | Thick Crust | Springfield |
| Vincenzo's Pizza | Thick Crust | Shelbyville |
| Vincenzo's Pizza | Thin Crust | Springfield |
| Vincenzo's Pizza | Thin Crust | Shelbyville |
The above example is not in 4NF, because, in this scenario, the pizza restaurants always offer the same options, regardless of what city they are in. Therefore, we can break this one table into two to make them 4NF - one table that lists the pizza menu by restaurant, and one that lists the pizza restaurants by city.
Fifth Normal Form (5NF)
The fifth normal form generalizes a rule that's already been functionally enforced in different ways by the other rules - if you can reduce redundancy with logic, you should do that.
To illustrate this, I'm going to borrow liberally from the great Bill Kent Opens in a new window.
-----------------------------
| AGENT | COMPANY | PRODUCT |
|-------+---------+---------|
| Smith | Ford | car |
| Smith | Ford | truck |
| Smith | GM | car |
| Smith | GM | truck |
| Jones | Ford | car |
-----------------------------Let's imagine the above example exists in a situation where we can say for certain, "if an agent sells a company's product, she represents that company", and "if an agent represents a company, the products she sells are the ones from that company". In that case, the above table is not in 5NF, because we can reduce redundancy if we know the rules.
The point of 5NF is not to minimize the number of rows, necessarily, but the number of times we need to state something to be true. We can take the above table and transform it into the tables below:
------------------- --------------------- -------------------
| AGENT | COMPANY | | COMPANY | PRODUCT | | AGENT | PRODUCT |
|-------+---------| |---------+---------| |-------+---------|
| Smith | Ford | | Ford | car | | Smith | car |
| Smith | GM | | Ford | truck | | Smith | truck |
| Jones | Ford | | GM | car | | Jones | car |
------------------- | GM | truck | -------------------
---------------------By adhering to 5NF, we now only have to state any fact once - Smith sells for Ford, or Jones sells cars, or GM sells trucks.
And that's about as far as we can go with database design principles without getting our hands dirty. Before we get to architecting in a serious way, however, we have a few more tools available to us that we're going to get familiar with in the 3 coming weeks: views, triggers, custom functions and stored procedures.