JOINS!
This week we'll cover coding INNER JOINs to retrieve rows from multiple tables; table aliases; JOIN with implicit INNER JOIN syntax.
Up to this point, we've been talking about how to work with data from single tables.
These tables contain data about different instances of the same kind of thing. If it's a 'students' table, each student gets a row. If it's a bike theft table, each theft gets a row.
Today we'll learn about what's really cool about RDBMSs like MySQL (which powers our bikeTheft database) and SQLite (which runs our in-browser queries).
Fair warning: joining tables is a concept that a lot of people stuggle with the first time, so I'm going to be explaining it a few different ways, but let's start with this:
In databases, we want to duplicate data as little as possible. If we didn't care about duplicating data, for example, a library could put someone's name, address, and phone number into the database every time they took out a book.
If they did this, and that person moved to a new address, they'd have to update the address in multiple rows (maybe hundreds? or thousands?).
If any one of those rows had a typo in the address, a search-and-replace operation might miss it.
Even if it worked perfectly every time, it's still very computationally expensive and an inefficient use of memory.
Instead, what we do is use a unique identifier (a "primary key") to identify each person*, so that we can write down their information once, and look it up when we need it.
The way we look stuff up is by creating references from one table to another by listing the primary key.
In a table for 'book withdrawals', we might have a column called 'who withdrew the book?' Instead of a name, address and phone number, we can just list the primary key of the person in the "library members" table, where names and addresses and such are stored.
Then, when we need to see that information, we can write a query that says, "don't just show me data from the 'book withdrawals' table, but also look up the information about the people that are referenced by the 'who withdrew the book?' column, and show their data in the same row in the results table".
That is, essentially, what a join does: combines data from multiple database tables into a single results table, based on rows that share the same data in a key column.
* ...and all other kinds of entities that we store in our tables.Putting the 'Relation' in 'Relational Database'
Relational databases can describe relationships between data. For instance, students and schools are two different types of thing, and they should have their own separate tables. But students attend school, and schools have students.

Think of the information we have about schools - addresses, phone numbers, etc.
Imagine we didn't have a table to hold all that information about the school. Our students table would have a bunch of redundant school information, and might look like this:

The school's data is redundant.
Imagine if we didn't have a table to hold all the student data, and just put students in the school table - we wouldn't know how many columns we needed!

The solution that relational databases offer is pretty simple. Instead of repeating information, we store it in one place only, and look it up!
Remember in week 1 when we talked about 'primary keys Opens in a new window'?
The keys to a good relationship
Primary keys are unique identifiers for each row of data. When the primary key of one table is listed in another table, that's a 'foreign key'.
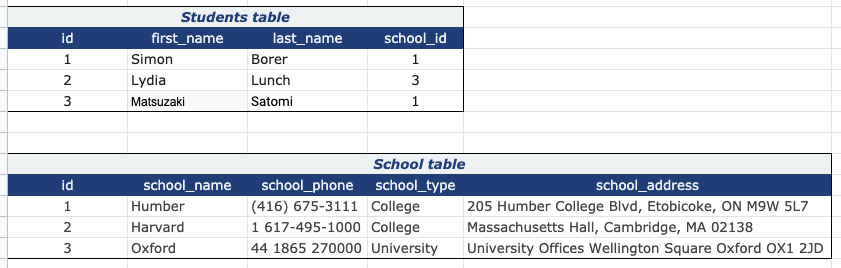
In this example, we've added a 'foreign key' to the students table that makes it easy to look up which school each student attends without duplicating any information. The 'school_id' column in the students table references the unique data in the 'id' column of the school table.
Naturally, these foreign keys aren't much help unless we can output the data that we're referencing. In SQL, we have a way to write a query, and return data from our initial table, plus the data that we're 'looking up' in the other table.
This is what's known as a 'JOIN', because we are joining together the data from multiple database tables into a single output table.
This week we'll be doing 'inner' joins. Next week we'll learn about other kinds of joins.

How to join
Here's the syntax we're going to use:
SELECT [columns]
FROM [table]
JOIN [otherTable]
ON [table].[column] = [otherTable].[column]We use the new clauses JOIN and ON to 'merge' the data from multiple tables.
JOIN just says 'in addition to the table referenced by our FROM clause, we're also going to look things up in this other table'.
ON creates the condition for putting data from different database tables into the same row in the results table. This is (almost always) the foreign key from one table and the primary key from the other.
This is how we 'look up' an entity (say, a school) from one table to put it alongside the entity it has a relationship with (say, a student who attends that school).

Questions we can answer with an inner join
Let's look at another example.
Say we have two tables: one for assignments, one for students.
Each assignment belongs to a class. Each student belongs to a class. If we use our join statement to "merge" these two tables, it will output a row for every instance of a match between the assignments table, and the students table. This tells us, based on what class a student is in, what assignment they have to do.
SELECT student, assignment
FROM assignments
JOIN students
ON assignments.class = students.class| Birinder | Lab |
| Ryan | Exam |
Notice that our results table doesn't show anything for the student 'Amandeep', or the assignment 'Paper'. That's because there wasn't a match for them in the other table.
What we're seeing in the results table answers the question "What assignments have been assigned to students?", or "Which students have assignments, and what are they assigned?"
It does not answer the question, "Which students have no assignments?", or "What are all the assignments, and who has been assigned them?"
We will use different types of joins (starting next week) to return results that don't have a 'match' in the joined table.
Wouldn't it be nice if you could spend all day writing out your JOINs without having to always look up which table has which columns by clicking on them individually in DBeaver? And wouldn't it be even better if you had some way of quickly visualizing the relationships between between tables?
Entity relationship diagrams

You can make your own!
DBeaver gives us two ways to generate an ER diagram.
1. If you double click on a table in the Database Navigator pane, you'll open up a panel of information about that table. One of the panel tabs is "ER Diagram", which show any direct relationships between the selected table and related tables in the database.
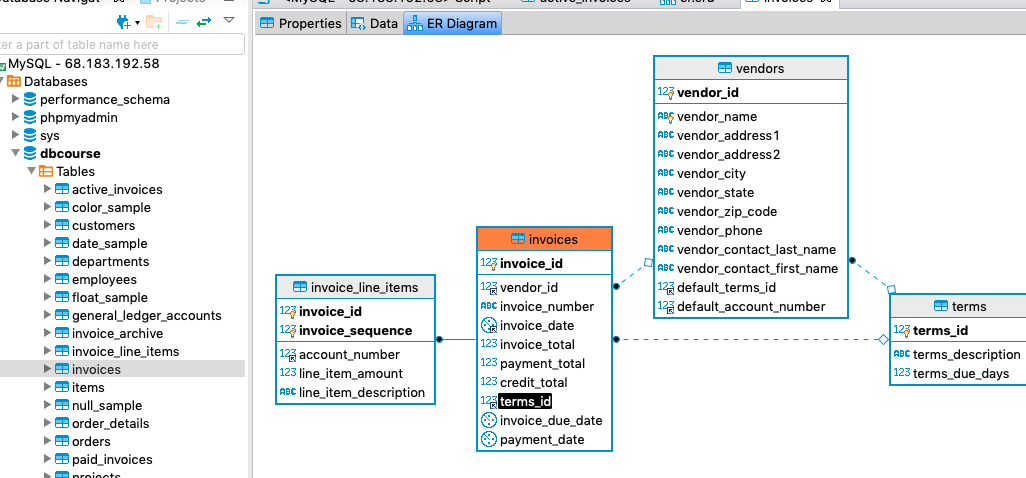
2. You can create a custom diagram by right-clicking on your connection, and selecting Create > Other... > ER Diagram > Next and selecting the tables you want to include in your diagram.
Either way, your diagram comes with a good amount of information, including all columns, their data types, keys, and, particularly helpful, lines representing the relationships.
This will particularly come in handy when you're...
Joining multiple tables
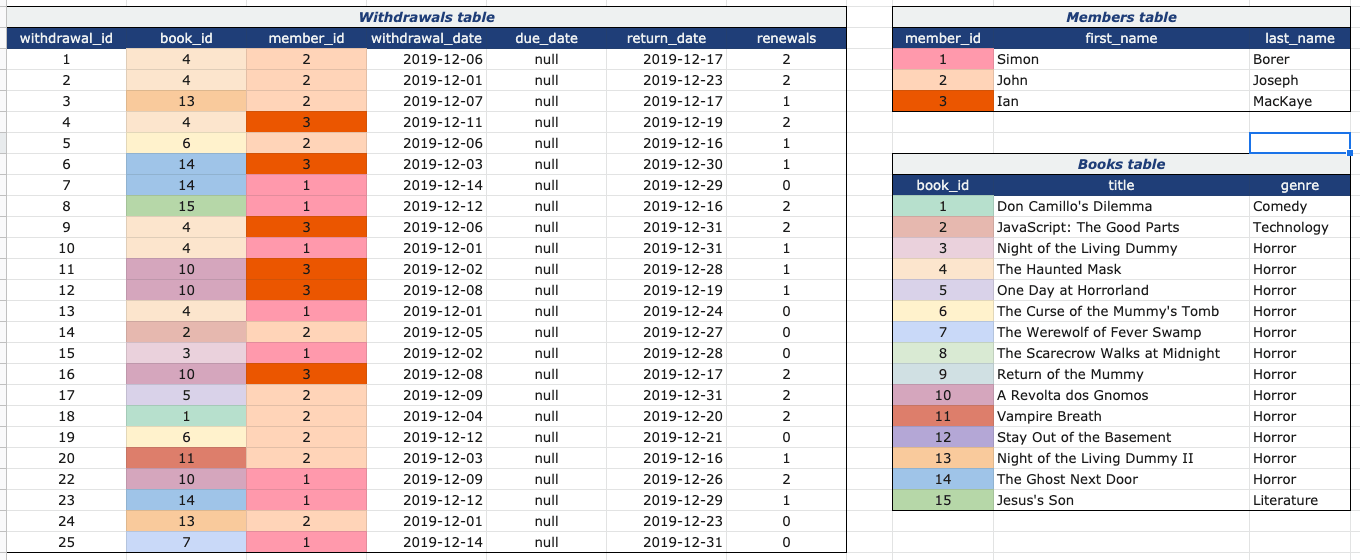
SELECT
title,
CONCAT(last_name, ", ", first_name) AS "Name",
withdrawal_date
FROM members
JOIN withdrawals
ON withdrawals.member_id = members.member_id
JOIN books
ON withdrawals.book_id = books.book_idTables can effectively be 'chained' together using joins.
This can come in particularly handy when using an intermediary table to break up a many-to-many relationship into two one-to-many relationships.

Aliases
When creating JOINs, it can get tedious writing out table names over and over. Luckily, we have the option to alias (i.e. give a nickname to) our tables.
SELECT
[tableAlias].[column],
[otherTableAlias].[column]
FROM [table] [tableAlias]
JOIN [otherTable] [otherTableAlias]
ON [tableAlias].[column] = [otherTableAlias].[column]One thing to note: if you create a column alias, you can't use [table].[column] - you have to use [tableAlias].[column]
This is a lighter week - there's no lab work assigned, and we'll essentially be doing a continuation of this topic next week (different kinds of joins, that kind of thing).
That being said, I want you to be able to try this stuff out if you'd like to.
In dBeaver, you might have to refresh your connection, by right clicking it in the 'Database Navigator' panel and selecting 'Refresh'.
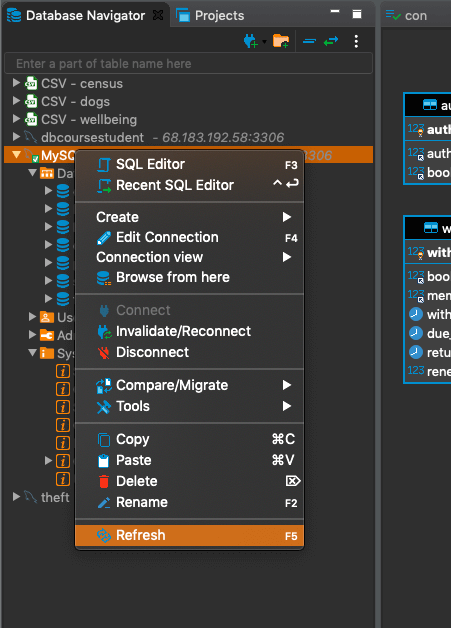
Then you'll want to right-click the 'library' database and select 'Set as default', so that you can write queries without having to specify which database you want to query.
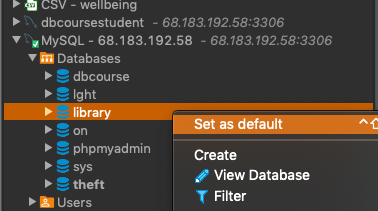
(If you want to go back to using the bike theft data after this, you'll want to set it to be the default again.)
Exercises
Try completing these exercises to see if you get it!
I highly encourage you to work on these, even though there are no grades at stake. Next week, we'll be talking about weird kinds of joins, so make sure you've got a firm grasp on inner joins as they are by far the most common type of join.
- In order to find out who took out books, and when: Get the withdrawals from the withdrawals table, then join the members table to include the first and last names of the people who made the withdrawals.
- Modifying this query, join the books table to the existing tables. Now get the names of the books that were withdrawn.
- Modifying this query again, order the results from the most recent withdrawal to the oldest.
- Use an aggregate function to get the top 5 most borrowed books.
- Get a list of books, including the titles, and the authors' first and last names.
- Modify this query so that it only returns books from a certain genre (you choose).
- Modify this query so that it only returns books from the 'Night of the Living Dummy' series. (Books in this series have a title that includes the words 'Night of the Living Dummy'.)
- Consider the following: why do we not put authors directly into the books table?